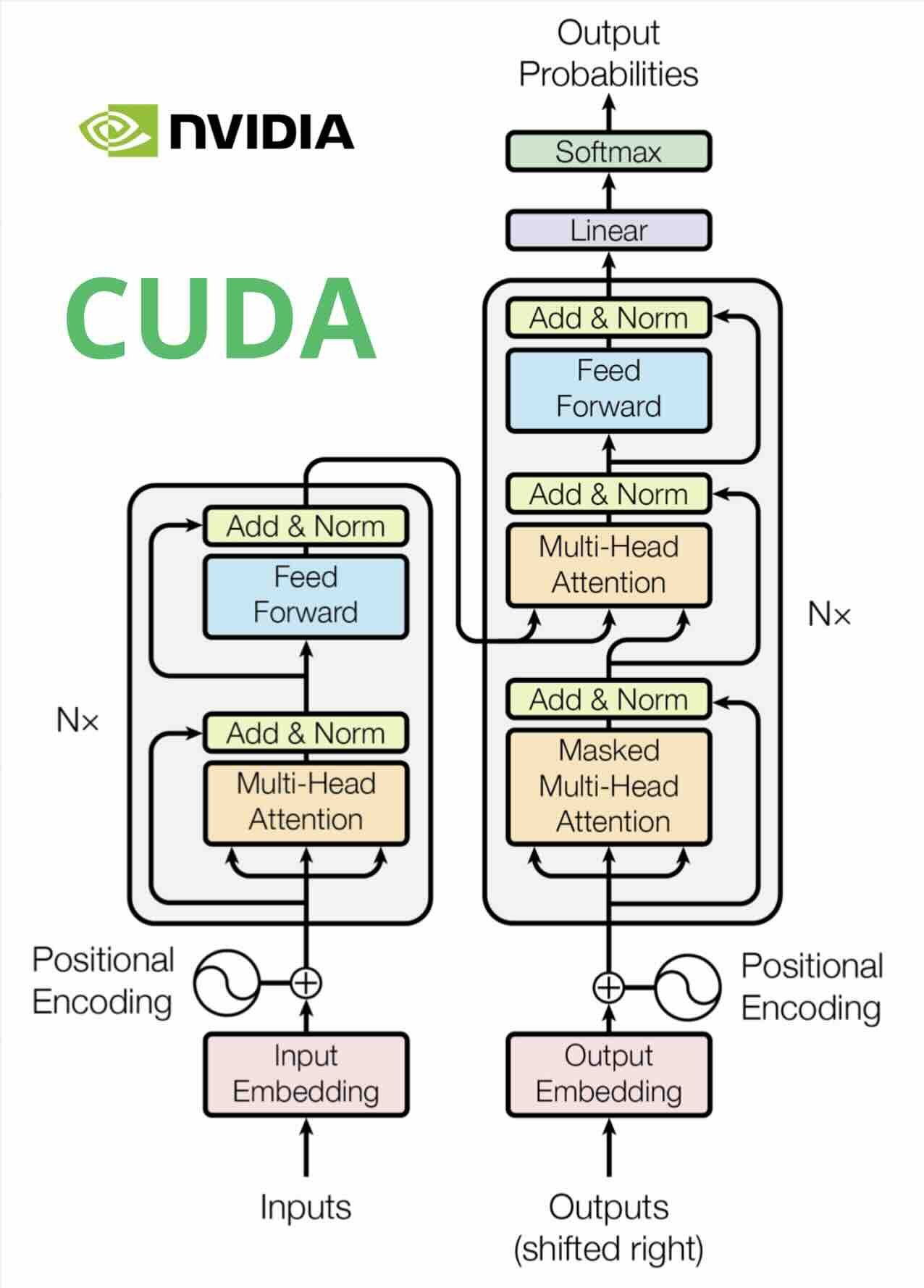
We've all heard of the famous 2017 AI paper "Attention is all you Need". I've re-implemented the paper in CUDA C++ to make the most efficient use of the GPU!
We've all heard of the famous 2017 AI paper "Attention is all you Need". I've re-implemented the paper in CUDA C++ to make the most efficient use of the GPU!
The Transformer architecture (Vaswani et al., 2017) — each layer including multi-head attention, feed-forward networks, and layer normalization implemented from scratch in CUDA C++.