How I trained and ran a Latent Diffusion AI Model on a Gaming PC
Training and inference of generative image models with latent diffusion from scratch on a gaming PC — I trained a generative image model end-to-end on a single consumer GPU in about a week, leveraging the Latent Diffusion framework (Rombach et al., 2022) to make this feasible without cloud compute. By applying the diffusion process in a compressed latent space rather than pixel space, and targeting the LSUN Churches dataset for its single-domain convergence properties, I brought training costs down from hundreds of GPU-days to just 5 on desktop hardware. The trained model generates novel architectural scenes from text prompts via CLIP-conditioned sampling with classifier-free guidance — a full text-to-image pipeline running locally, no cloud required.
I trained a Latent Diffusion Model (Rombach et al., 2022) from scratch on a single consumer GPU — the kind you'd find in a gaming desktop and used it to generate novel images via text-conditioned sampling with CLIP embeddings. The key insight that makes this feasible is in the name: latent diffusion. Traditional diffusion models operate directly in pixel space, making training prohibitively expensive — on the order of hundreds of GPU-days even for modest resolutions. LDM sidesteps this by first encoding images into a compressed latent representation using a pretrained KL-regularized autoencoder (f=8, yielding 32x32x4 latent maps from 256x256 images), then applying the forward and reverse diffusion processes entirely in that lower-dimensional space. This reduces the computational cost by orders of magnitude without sacrificing perceptual quality.
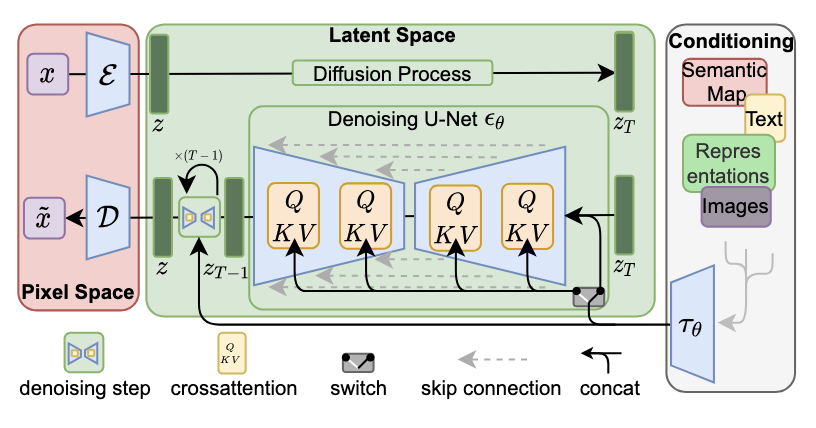
To further keep training times practical on a single GPU, I chose the LSUN Churches dataset rather than ImageNet. Churches is a single-domain dataset with strong structural consistency, which means the model converges faster than it would on ImageNet's 1000-class distribution. With this setup, end-to-end training completed in roughly one week — well within reach for anyone with a modern gaming card and some patience. For inference, I use DDIM sampling with classifier-free guidance, conditioning on CLIP text embeddings to steer generation. The result: a locally-trained generative model that synthesizes novel architectural scenes from text prompts, running entirely on desktop hardware.







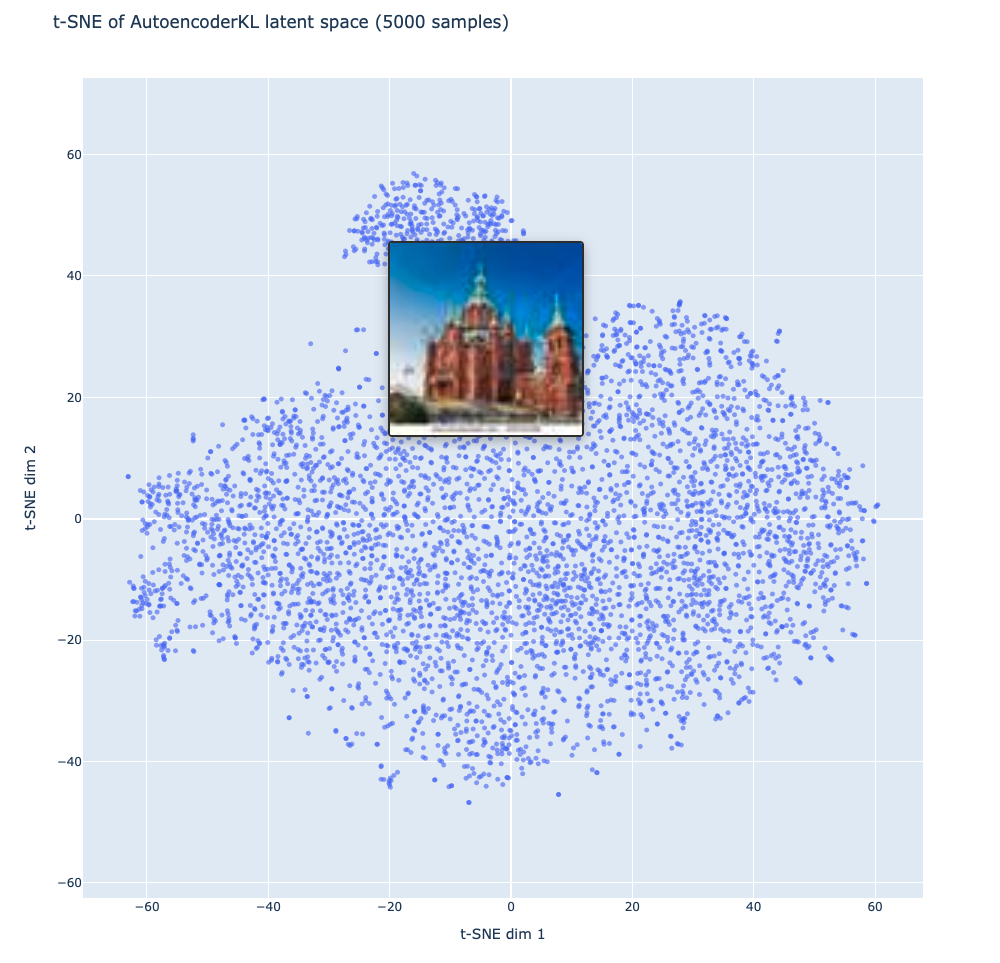
I also performed a PCA + t-SNE analysis to the latent space representations of the training set images, the results of which are displayed at the following link. Overall, since all the images are in the same "Church" class, they appear as 1 diffuse blob in the latent space with similar church images close together in that space.